Before we devise our parallelization strategy, let’s first go over the serial program, as shown in the following listing, so we understand how each step works.
Listing 7.1 Serial implementation of the weather buoy processing program
program weather_stats
use mod_arrays, only: denan, mean ❶
use mod_io, only: read_buoy ❷
implicit none
character(5), allocatable :: ids(:)
character(20), allocatable :: time(:) ❸
real, allocatable :: wind_speed(:) ❸
real, allocatable :: max_wind(:), mean_wind(:) ❹
integer :: i
ids = ['42001', '42002', '42003', '42020', '42035', & ❺
'42036', '42039', '42040', '42055'] ❺
allocate(max_wind(size(ids)), mean_wind(size(ids))) ❻
do i = 1, size(ids) ❼
call read_buoy('data/buoy_' // ids(i) // '.csv', & ❽
time, wind_speed) ❽
wind_speed = denan(wind_speed) ❾
max_wind(i) = maxval(wind_speed) ❿
mean_wind(i) = mean(wind_speed) ❿
end do
print *, 'Maximum wind speed measured is ', & ⓫
maxval(max_wind), 'at station ', ids(maxloc(max_wind))
print *, 'Highest mean wind speed is ', & ⓫
maxval(mean_wind), 'at station ', ids(maxloc(mean_wind))
print *, 'Lowest mean wind speed is ', ⓫
minval(mean_wind), 'at station ', ids(minloc(mean_wind))
end program weather_stats❶ Helper functions for working with arrays
❷ Subroutine to read the buoy CSV data
❸ Dynamic arrays for timestamps and wind speed
❹ Temporary arrays for maximum and mean wind speed
❻ Allocates maximum and mean wind speeds
❽ Reads buoy file and stores timestamps and wind speed in arrays
❿ Calculate maximum and mean values for this buoy
⓫ Writes the results to screen
We use this array to determine both the number of buoys to process and the data file names. We allocate the dynamic arrays max_wind and min_wind to be of the same length as ids. We’ll use these arrays to store intermediate results: maximum and mean values for each buoy. The bulk of the work happens within the do loop and consists of the following:
- Reading the data using the
read_buoysubroutine, and storing it into thewind_speedarray - Removing missing values (
nan) using thedenanfunction - Calculating the maximum wind speed using the
maxvalbuilt-in function - Calculating the mean wind speed using the
meanfunction
Finally, we use the minval, maxval, minloc, and maxloc built-in functions to find the minimum and maximum values, and their respective indices, of the arrays max_wind and min_wind. Whereas inside the do loop we were evaluating maxima in time for each buoy, at this step we compare the values between buoys. Figure 7.5 illustrates the program flow.
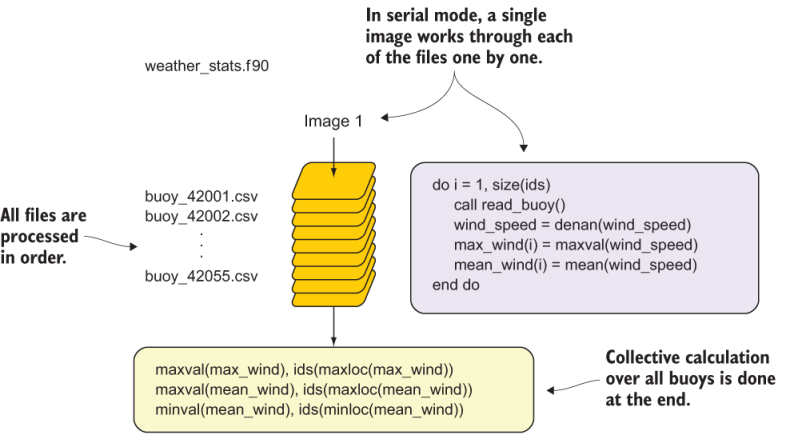
Figure 7.5 The flow of the serial weather_stats program. “Image 1” here refers to a single serial core or CPU.
Note that for removing missing data (not a number (NaN)) and calculating the mean value of the arrays, we defer to the external functions denan and mean, respectively. To see how they’re implemented, take a peek inside src/mod_arrays.f 90. If you’re interested in how the CSV data reader (read_buoy) works, it’s defined in src/mod _io.f 90. The main program is defined in src/weather_stats.f 90.
If you cloned the repository from GitHub and installed OpenCoarrays (see appendix A), you’re good to go! Inside the weather-buoys directory, type make weather_stats to build the serial program, and run it by typing ./weather_stats.
Note that the weather_stats program doesn’t use any coarrays or other parallel features at this point. However, for simplicity, the repository is configured to build using the OpenCoarrays wrapper caf, which can be used to build both serial and parallel programs.
How can we parallelize the program in listing 7.1 in the most straightforward way? What you need to look for is what region of the program repeats over different inputs. Recall the discussion about embarrassingly parallel problems in chapter 1. They’re the kind of problems where you can break the input data down into pieces and work on each piece independently, regardless of the rest of the data. In the weather_stats program, the do loop over the buoy data files is like that:
do i = 1, size(ids)
call read_buoy('data/buoy_' // ids(i) // '.csv', time, wind_speed)
wind_speed = denan(wind_speed)
max_wind(i) = maxval(wind_speed)
mean_wind(i) = mean(wind_speed)
end doIf I loop over the buoys in any order, I’ll still end up with the same result for max_wind and mean_wind. This means that I can safely dispatch the processing of each buoy file to a different processing core or thread. However, this also means that the elements of max_wind and mean_wind will be scattered across the parallel processes. To calculate the global minima and maxima across all buoys, we’ll need to gather the data on one processor. This is where Fortran coarrays come in.