In most scientific and engineering parallel applications, there’s data dependency between processes. Typically, a two-dimensional array is decomposed into tiles like a chessboard, and the workload of each tile is assigned to a processor. Each tile has its own data in memory that’s local to its processor. To illustrate the simplest case of parallel programming in a real-world scenario, let’s take the following meteorological situation for example. Suppose that the data consists of two variables: wind and air temperature. Wind is blowing from one tile with a lower temperature (cold tile) toward another tile with a higher temperature (warm tile). If we were to solve how the temperature evolves over time, the warm tile would need to know what temperature is coming in with the wind from the cold tile. Because this is not known a priori (remember that the data is local to each tile), we need to copy the data from the cold tile into the memory that belongs to the warm tile. On the lowest level, this is done by explicitly copying the data from one processor to another. When the copy is finished, the processors can continue with the remaining computations. Copying one or more values from one process to another is the most common operation done in parallel programming (figure 1.6).
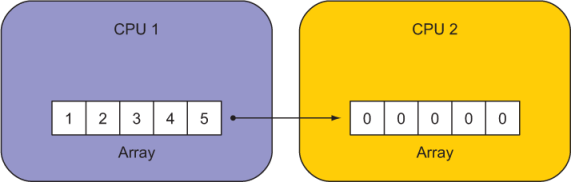
Figure 1.6 An illustration of a remote array copy between two CPUs. Numbers inside the boxes indicate initial array values. Our goal is to copy values of array from CPU 1 to CPU 2.
Let’s focus on just this one operation. Our goal is to do the following:
- Initialize
arrayon each process–[1,2,3,4,5]on CPU 1 and all zeros on CPU 2. - Copy values of
arrayfrom CPU 1 to CPU 2. - Print the new values of
arrayon CPU 2. These should be[1,2,3,4,5].
I’ll show you two example solutions to this problem. One is the traditional approach using an external library like MPI. Unless you’re a somewhat experienced Fortran programmer, don’t try to understand every detail in this example. I merely want to demonstrate how complicated and verbose it is. Then, I’ll show you the solution using coarrays. In contrast to MPI, coarrays use an array indexing-like syntax to copy remote data between parallel processes.
MPI: The traditional way to do parallel programming
As noted before, MPI is often described as the assembly language of parallel programming, and, indeed, that was its developers’ original intention. MPI was meant to be implemented by compiler developers to enable natively parallel programming languages. Over the past three decades, however, application developers have been faster at adopting MPI directly in their programs, and it has become, for better or worse, a de facto standard tool for parallel programming in Fortran, C, and C++. As a result, most HPC applications today rely on low-level MPI calls.
The following Fortran program sends data from one process to another using MPI.
Listing 1.2 Copying an array from one process to another using MPI
program array_copy_mpi
use mpi ❶
implicit none
integer :: ierr, nproc, procsize, request
integer :: stat(mpi_status_size)
integer :: array(5) = 0
integer, parameter :: sender = 0, receiver = 1
call mpi_init(ierr) ❷
call mpi_comm_rank(mpi_comm_world, nproc, ierr) ❸
call mpi_comm_size(mpi_comm_world, procsize, ierr) ❹
if (procsize /= 2) then ❺
call mpi_finalize(ierr) ❺
stop 'Error: This program must be run & ❺
on 2 parallel processes' ❺
end if ❺
if (nproc == sender) array = [1, 2, 3, 4, 5] ❻
print '(a,i1,a,5(4x,i2))', 'array on proc ', nproc, & ❼
' before copy:', array ❼
call mpi_barrier(mpi_comm_world, ierr) ❽
if (nproc == sender) then
call mpi_isend(array, size(array), mpi_int, & ❾
receiver, 1, mpi_comm_world, request, ierr) ❾
else if (nproc == receiver) then
call mpi_irecv(array, size(array), mpi_int, & ❿
sender, 1, mpi_comm_world, request, ierr) ❿
call mpi_wait(request, stat, ierr) ⓫
end if
print '(a,i1,a,5(4x,i2))', 'array on proc ', nproc, &
' after copy: ', array
call mpi_finalize(ierr) ⓫
end program array_copy_mpi❶ Accesses MPI subroutines and the mpi_comm_world global variable from a module
❸ Which processor number am I?
❹ How many processes are there?
❺ Shuts down MPI and stops the program if we’re not running on two processors
❻ Initializes array on sending process
❼ Prints text to screen with specific formatting
❽ Waits here for both processes
❾ Sender posts a nonblocking send
❿ Receiver posts a nonblocking receive
⓫ Receiver waits for the message
⓫ Finalizes MPI at the end of the program
Running this program on two processors outputs the following:
array on proc 0 before copy: 1 2 3 4 5 array on proc 1 before copy: 0 0 0 0 0 array on proc 0 after copy: 1 2 3 4 5 array on proc 1 after copy: 1 2 3 4 5
This confirms that our program did what we wanted: copied the array from process 0 to process 1.
Compiling and running the examples
Don’t worry about building and running these examples yourself for now. At the start of the next chapter, I’ll ask you to set up the complete compute environment for working with examples in this book, including this example. If you prefer, you can follow the instructions in appendix A now instead of waiting.
Enter Fortran coarrays
Coarrays are the main data structure for native parallel programming in Fortran. Originally developed by Robert Numrich and John Reid in the 1990s as an extension for the Cray Fortran compiler, coarrays have been introduced into the standard starting with the 2008 release. Coarrays are much like arrays, as the name implies, except that their elements are distributed along the axis of parallel processes (cores or threads). As such, they provide an intuitive way to copy data between remote processes.
The following listing shows the coarray version of our array copy example.
Listing 1.3 Copying an array from one process to another using coarrays
program array_copy_caf
implicit none
integer :: array(5)[*] = 0 ❶
integer, parameter :: sender = 1, receiver = 2
if (num_images() /= 2) & ❷
stop 'Error: This program must be run on 2 parallel processes'
if (this_image() == sender) array = [1, 2, 3, 4, 5] ❸
print '(a,i2,a,5(4x,i2))', 'array on proc ', this_image(), &
' before copy:', array
sync all ❹
if (this_image() == receiver) & ❺
array(:) = array(:)[sender] ❺
print '(a,i1,a,5(4x,i2))', 'array on proc ', this_image(), &
' after copy: ', array
end program array_copy_caf❶ Declares and initializes an integer coarray
❷ Throws an error if we’re not running on two processes
❹ Waits here for all images; equivalent to mpi_barrier()
❺ Nonblocking copy from sending image to receiving image
The output of the program is the same as in the MPI variant:
array on proc 1 before copy: 1 2 3 4 5
array on proc 2 before copy: 0 0 0 0 0
array on proc 1 after copy: 1 2 3 4 5
array on proc 2 after copy: 1 2 3 4 5These two programs are thus semantically the same. Let’s look at the key differences in the code:
- The number of lines of code (LOC) dropped from 27 in the MPI example to 14 in the coarray example. That’s almost a factor of 2 decrease. However, if we look specifically for MPI-related boilerplate code, we can count 15 lines of such code. Compare this to two lines of code related to coarrays! As debugging time is roughly proportional to the LOC, we see how coarrays can be more cost-effective for developing parallel Fortran apps.
- The core of the data copy in the MPI example is quite verbose for such a simple operationif (nproc == 0) then call mpi_isend(array, size(array), mpi_int, receiver, 1, & mpi_comm_world, request, ierr) else if (nproc == 1) then call mpi_irecv(array, size(array), mpi_int, sender, 1, & mpi_comm_world, request, ierr) call mpi_wait(request, stat, ierr) end ifcompared to the intuitive array-indexing and assignment syntax of coarrays:if (this_image() == receiver) array(:) = array(:)[sender]
- Finally, MPI needs to be initialized and finalized using
mpi_init()andmpi_ finalize()subroutines. Coarrays need no such code. This one is a minor but welcome improvement.
Did you notice that our parallel processes were indexed 0 and 1 in the MPI example and 1 and 2 in the coarray example? MPI is implemented in C, in which array indices begin at 0. In contrast, coarray images start at 1 by default.
As we saw in this example, both MPI and coarrays can be used effectively to copy data between parallel processes. However, MPI code is low-level and verbose, and would soon become tedious and error-prone as your app grows in size and complexity. Coarrays offer an intuitive syntax analogous to the array operations. Furthermore, with MPI, you tell the compiler what to do; with coarrays, you tell the compiler what you want, and let it decide how best to do it. This lifts a big load of responsibility off your shoulders and lets you focus on your application. I hope this convinces you that Fortran coarrays are the way to go for expressive and intuitive data copy between parallel processes.
A partitioned global address space language
Fortran is a partitioned global address space (PGAS) language. In a nutshell, PGAS abstracts the distributed-memory space and allows you to do the following:
- View the memory layout as a shared-memory space –This will give you a tremendous boost in productivity and ease of programming when designing parallel algorithms. When performing data copy, you won’t need to translate or transform array indices from one image to another. Memory that belongs to remote images will appear as local, and you’ll be able to express your algorithms in such a way.
- Exploit the locality of reference –You can design and code your parallel algorithms without foresight about whether a subsection of memory is local to the current image or not. If it is, the compiler will use that information to its advantage. If not, the most efficient data copy pattern available will be performed.
PGAS allows you to use one image to initiate a data copy between two remote images:
if (this_image() == 1) array(:)[7] = array(:)[8]The if statement ensures that the assignment executes only on image 1. However, the indices inside the square brackets refer to images 7 and 8. Image 1 will thus asynchronously request an array copy from image 8 to image 7. From our point of view, the indices inside the square brackets can be treated just like any other array elements that are local in memory. In practice, these images could be mapped to different cores on the same shared-memory computer, across the server room, or even around the world.