For over a decade prophets have voiced the contention that the organization of a single computer has reached its limits and that truly significant advances can be made only by interconnection of a multiplicity of computers in such a manner as to permit cooperative solution.
–Gene Amdahl (computer architect) in 1967
Parallel programming is only becoming more important with time. Although still positive, the rate of semiconductor density increase, as described by Moore’s law, is limited. Traditionally we went past this limit by placing more processing cores on a single die. Even the processors in most smartphones today are multicore. Beyond the shared-memory computer, we’ve connected many machines into networks, and made them talk to each other to solve huge computational problems. Your weather forecast this morning was computed on hundreds or thousands of parallel processors. Due to the practical limits of Moore’s law and the current tendency toward many-core architectures, there’s a sense of urgency to teach programming parallel-first.
Gordon Moore, cofounder of Intel, noticed in 1965 that the number of transistors in a CPU was doubling each year. He later revised this trend to doubling every two years. Nevertheless, the rate of increase is exponential and closely related to a continuous decrease in the cost of computers. A computer you buy today for $1,000 is about twice as powerful as one you could buy for the same amount two years ago.
Similarly, when you buy a new smartphone, the OS and the apps run smoothly and quickly. What happens two years later? As the apps update and bloat with new features, they demand increasingly more CPU power and memory. As the hardware in your phone stays the same, eventually the apps slow down to a crawl.
All parallel problems fall into two categories:
- Embarrassingly parallel –And by this, I mean “embarrassingly easy”–it’s a good thing! These problems can be distributed across processors with little to no effort (figure 1.4, left). Any function
f(x)that operates element-wise on an arrayxwithout need for communication between elements is embarrassingly parallel. Because the domain decomposition of embarrassingly parallel problems is trivial, modern compilers can often autoparallelize such code. Examples include rendering graphics, serving static websites, or processing a large number of independent data records. - Nonembarrassingly parallel –Any parallel problem with interdependency between processes requires communication and synchronization (figure 1.4, right). Most partial differential equation solvers are nonembarrassingly parallel. The relative amount of communication versus computation dictates how well a parallel problem can scale. The objective for most physical solvers is thus to minimize communication and maximize computation. Examples are weather prediction, molecular dynamics, and any other physical process that’s described by partial differential equations. This class of parallel problems is more difficult and, in my opinion, more interesting!
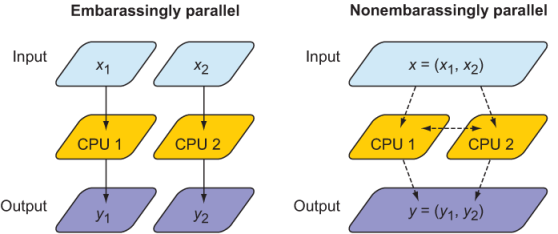
Figure 1.4 An embarrassingly parallel problem (left) versus a nonembarrassingly parallel problem (right). In both cases, the CPUs receive input (x1, x2) and process it to produce output (y1, y2). In an embarrassingly parallel problem, x1 and x2 can be processed independently of each other. Furthermore, both input and output data are local in memory to each CPU, indicated by solid arrows. In a nonembarrassingly parallel problem, input data is not always local in memory to each CPU and has to be distributed through the network, indicated by dashed arrows. In addition, there may be data interdependency between CPUs during the computation step, which requires synchronization (horizontal dashed arrow).
Why is it called embarrassingly parallel?
It refers to overabundance, as in an embarrassment of riches. It’s the kind of problem that you want to have. The term is attributed to Cleve Moler, inventor of MATLAB and one of the authors of EISPACK and LINPACK, Fortran libraries for numerical computing. LINPACK is still used to benchmark the fastest supercomputers in the world.
Because our application domain deals mainly with nonembarrassingly parallel problems, we’ll focus on implementing parallel data communication in a clean, expressive, and minimal way. This will involve both distributing the input data among processors (downward dashed arrows in figure 1.4) and communicating data between them (horizontal dashed arrow in figure 1.4).
Parallel Fortran programming in the past has been done either using the OpenMP directives for shared-memory computers only, or with the Message Passing Interface (MPI) for both shared and distributed memory computers. Differences between shared-memory (SM) and distributed-memory (DM) systems are illustrated in figure 1.5. The main advantage of SM systems is very low latency in communication between processes. However, there’s a limit to the number of processing cores you can have in an SM system. Since OpenMP was designed for SM parallel programming exclusively, we’ll focus on MPI for our specific example.
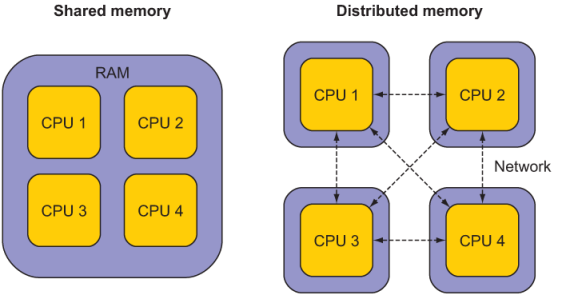
Figure 1.5 A shared-memory system (left) versus a distributed-memory system (right). In a shared-memory system, processors have access to common memory (RAM). In a distributed-memory system, each processor has its own memory, and they exchange data through a network, indicated by dashed lines. The distributed-memory system is most commonly composed of multicore shared-memory systems.
OpenMP is a set of directives that allows the programmer to indicate to the compiler the sections of code that are to be parallelized. OpenMP is implemented by most Fortran compilers and doesn’t require external libraries. However, OpenMP is limited to shared-memory machines.
Message Passing Interface (MPI) is a standardized specification for portable message passing (copying data) between arbitrary remote processes. This means that MPI can be used for multithreading on a single core, multicore processing on a shared-memory machine, or distributed-memory programming across networks. MPI implementations typically provide interfaces for C, C++, and Fortran. MPI is often described as the assembly language of parallel programming, illustrating the fact that most MPI operations are low-level.
Although still ubiquitous in HPC, OpenMP and MPI are specific approaches to parallel computing that can be more elegantly expressed with coarrays. This book will focus on coarrays exclusively for parallel programming.